PRoFENCH: A Systematic Study of Multimodal Fusion and Generalization in WiFi–Vision Wireless Sensing for People Counting
a Faculty of Information Science and Engineering, University of Information Technology, Ho Chi Minh City, 700000, Vietnam
b Faculty of Computer Networks and Communications, University of Information Technology, Ho Chi Minh City, 700000, Vietnam
c Vietnam National University Ho Chi Minh City, Ho Chi Minh City, 700000, Vietnam
d Ho Chi Minh City University of Industry and Trade, Vietnam, Ho Chi Minh City, 700000, Vietnam
Introduction
Visualization of the Data of each modality and their corresponding estimations.
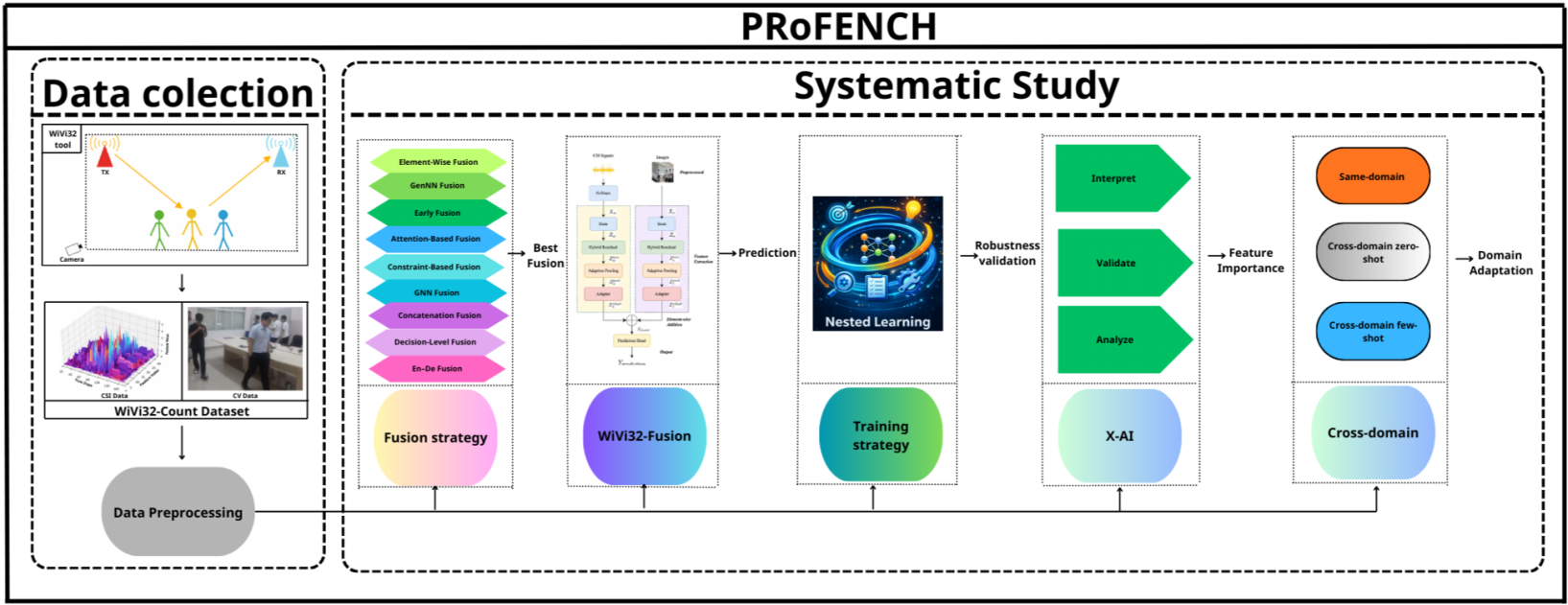
Figure 1: Architecture of the proposed PRoFENCH multimodal WiFi–Vision sensing framework.
Abstract
Device-free human sensing using WiFi Channel State Information (CSI) has shown strong potential for people counting in intelligent environments, due to its ability to operate reliably without relying on lighting conditions or direct visibility. However, single-modality approaches based on either WiFi or vision often suffer from limited accuracy and robustness, especially under challenging conditions such as occlusion, low illumination, and environmental variations. Multimodal sensing that combines WiFi and vision offers a promising solution by leveraging complementary information from both modalities. Nevertheless, several critical challenges remain, including the lack of low-cost synchronized data acquisition platforms, the scarcity of public multimodal datasets under adverse conditions, and the absence of systematic studies on fusion strategies and cross-domain generalization. In this work, we propose PRoFENCH, a comprehensive WiFi–Vision multimodal sensing framework for people counting. We first develop a low-cost synchronized sensing platform and introduce a unique public multimodal dataset collected under occlusion and low-light conditions. We then propose WiVi32-Fusion, a lightweight fusion model, and conduct a systematic evaluation of multiple multimodal fusion strategies. In addition, we integrate a nested learning mechanism and perform analyses on explainability, robustness, and cross-domain generalization. Experimental results show that the proposed framework achieves a low mean absolute error (MAE) of 0.12 and maintains stable performance across different domains. These results demonstrate the effectiveness, robustness, and practical applicability of the proposed framework for real-world multimodal human sensing. Keywords: WiFi–Vision multimodal sensing, Wireless human sensing, People counting, Multimodal fusion, Cross-domain generalization
Dataset
Counting People RGB
CV
0 VOLUNTEERS
1 VOLUNTEERS
2 VOLUNTEERS
3 VOLUNTEERS
4 VOLUNTEERS
5 VOLUNTEERS
6 VOLUNTEERS
7 VOLUNTEERS
CSI
0 VOLUNTEERS
1 VOLUNTEERS
2 VOLUNTEERS
3 VOLUNTEERS
4 VOLUNTEERS
5 VOLUNTEERS
6 VOLUNTEERS
7 VOLUNTEERS
Methodology
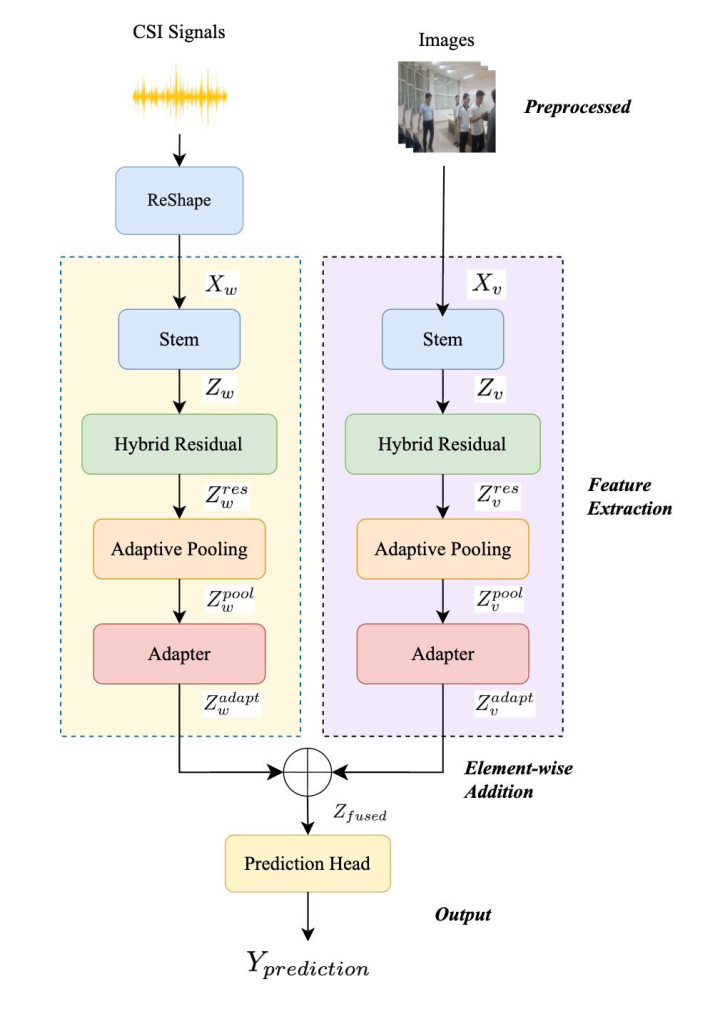
Figure 2: Overall architecture of the proposed WiVi32-Fusion framework.
Sensor Platform
Experimental Setup
(a) Layout

(b) Experiment Setup
ESP32 Communication Reliability
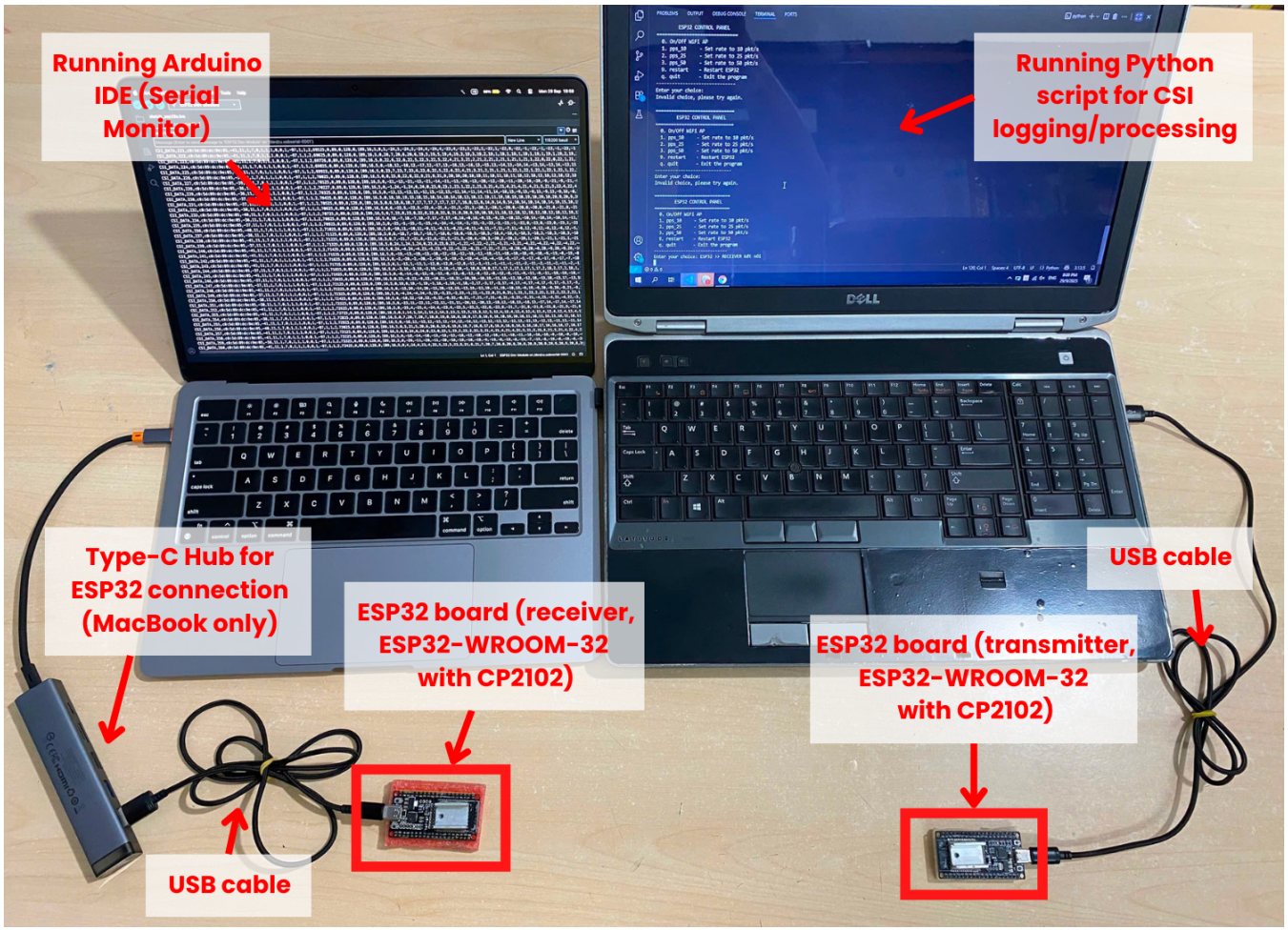
Figure 4: Overview of the experimental hardware setup, highlighting ESP32 modules, laptops, USB connections, and monitoring devices.
Figure 5: Software architecture and data flow between ESP32 devices, laptops, backend processing, and the React Native frontend.
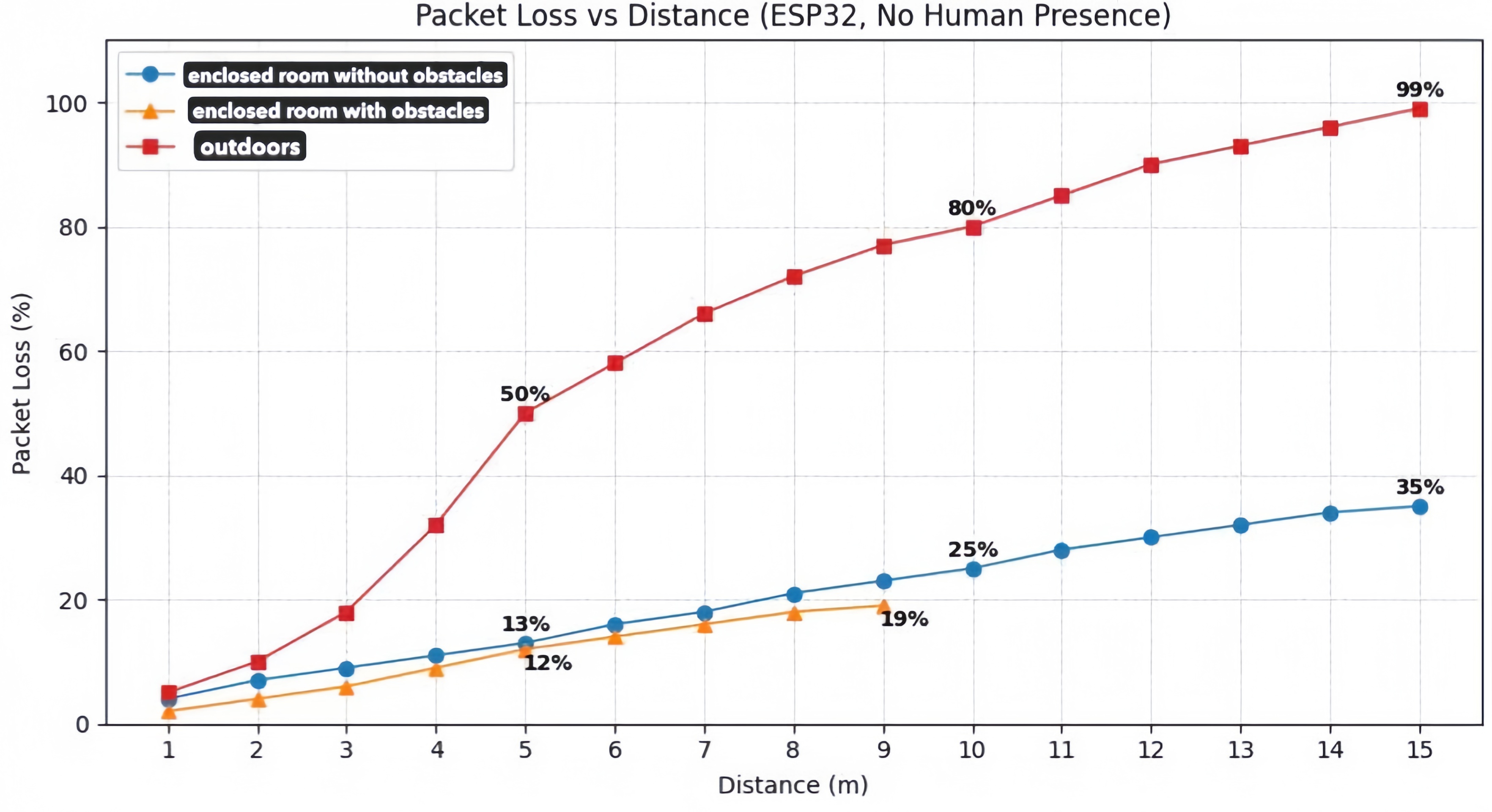
Figure 6: Packet loss rate of ESP32 communication under varying distances and environments. Indoor environments maintain stable communication performance, while outdoor environments exhibit rapid degradation due to signal attenuation and environmental factors.
Training Configuration
Figure 7: Visualization of the WiVi32-Count dataset across eight classes, showing Wi-Fi CSI signals (top) paired with corresponding camera images (bottom).
Human Pose Estimation Result
Counting People RGB
CV
CSI
License
This research is funded by Vietnam National University HoChiMinh City (VNU-HCM) under a project within the framework of the Program titled “Strengthening the capacity for education and basic scientific research integrated 23 with strategic technologies at VNU-HCM, aiming to achieve advanced standards comparable to regional and global levels during the 2025-2030 period, with a vision toward 2045.